Analyzing 1000 Data Science Books on Amazon : Insights and Trends
Motivation
I am passionate about data science and have always been fascinated by the possibilities it offers to understand and analyze data in order to extract useful insights. That's why I decided to undertake a data science project titled 'Analyzing 1000 Data Science Books on Amazon: Insights and Trends'.
By completing this project, I developed new skills in data science, particularly in the areas of text vectorization, text sentiment analysis, and text summary. These skills were particularly useful in analyzing the data to extract the most relevant insights and trends.
This project also allowed me to put my knowledge and skills in data science into practice while learning new techniques and approaches. I was motivated by the opportunity to discover new trends and insights about data science books on Amazon.
I was also motivated by the opportunity to develop my skills in data science and to improve in this discipline. This project offered me the opportunity to work with real data and to put my knowledge and skills acquired through my training and previous experiences into practice.
Content
In this project, I analyzed 1000 data science books on Amazon in order to uncover the most relevant trends and insights. My primary goal was to answer several key questions:
- Do more expensive books have better reviews?
- Do longer books have higher prices?
- What are the best Python books? What are the best ML books?
- What is the result of cluster analysis of book names/TF-IDF and K-means?
- How did I succeed in scraping Amazon reviews and summarizing book reviews?
To answer these questions, I used various data science techniques and approaches, including exploratory data analysis (EDA), text sentiment analysis, cluster analysis, and text vectorization. I also utilized data scraping techniques to gather Amazon reviews and implemented an automated summary of book reviews. In this article, I will present the results of my project and share my most interesting insights and trends.
Step 1 - Exploratory Data Analysis
a- Price vs Review
Do more expensive books have better reviews?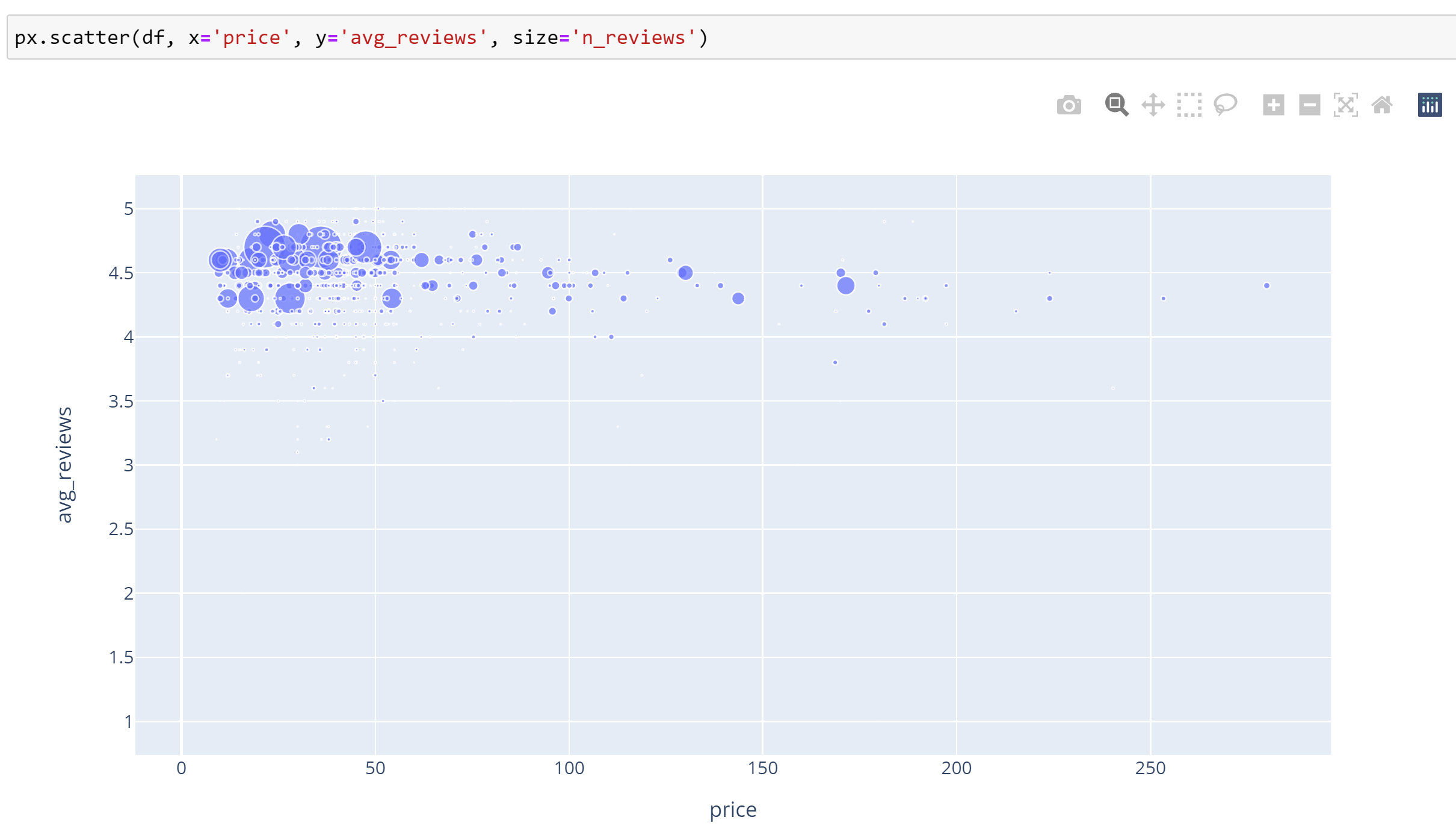
Based on the scatter plot, there is no clear relationship between the price of a book and its reviews.
b-Number of page Vs Price
Do longer books have higher prices?
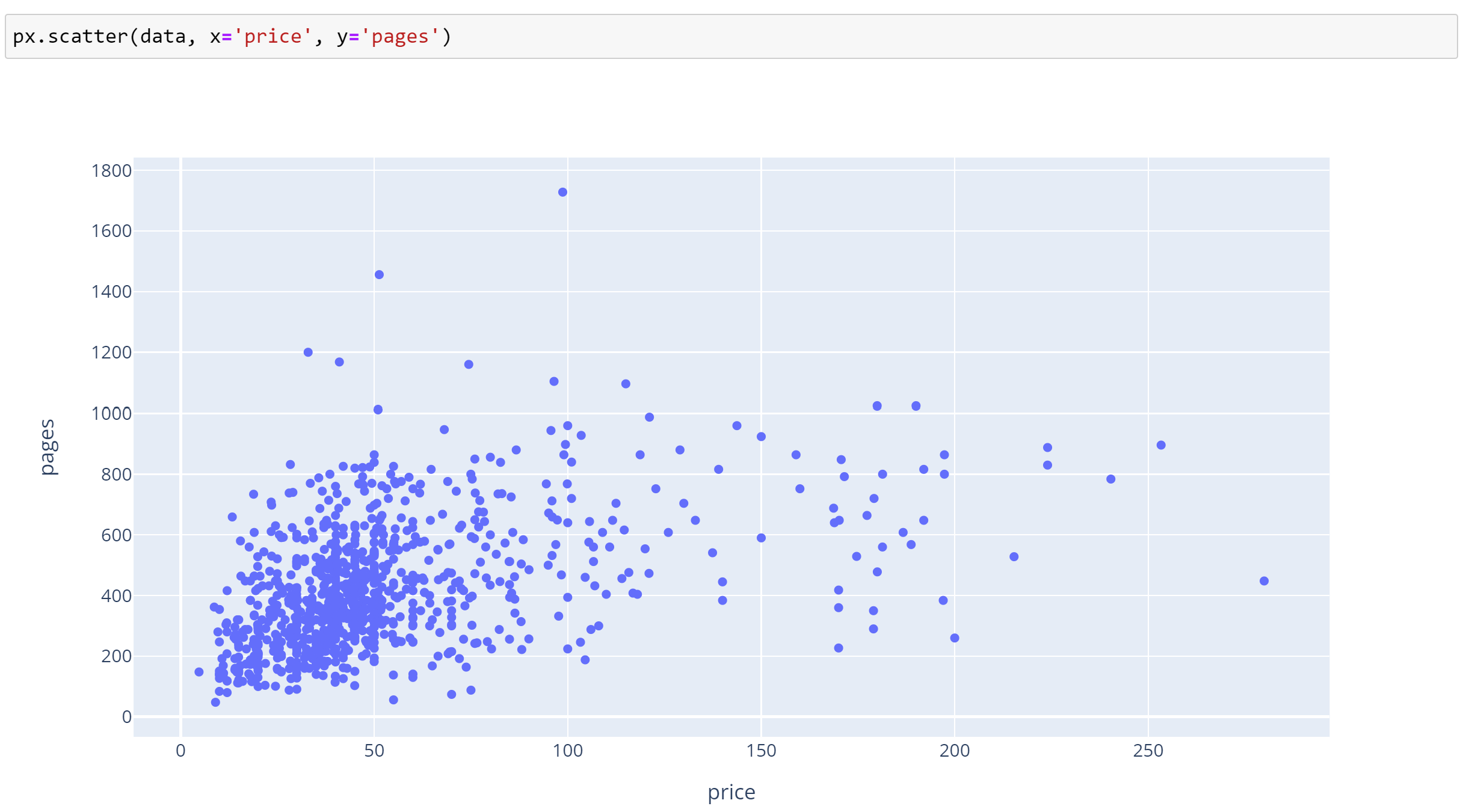
In conclusion, it appears that the longest books tend to be the ones that sell for the highest price. This makes sense in terms of content (more content in a larger book) and manufacturing cost. However, it is important to note that this trend may also be influenced by other factors such as the reputation of the author and the demand for the subject matter.
c-Best Python Books
What is the Top 5 Python books based on number of review and average review score ?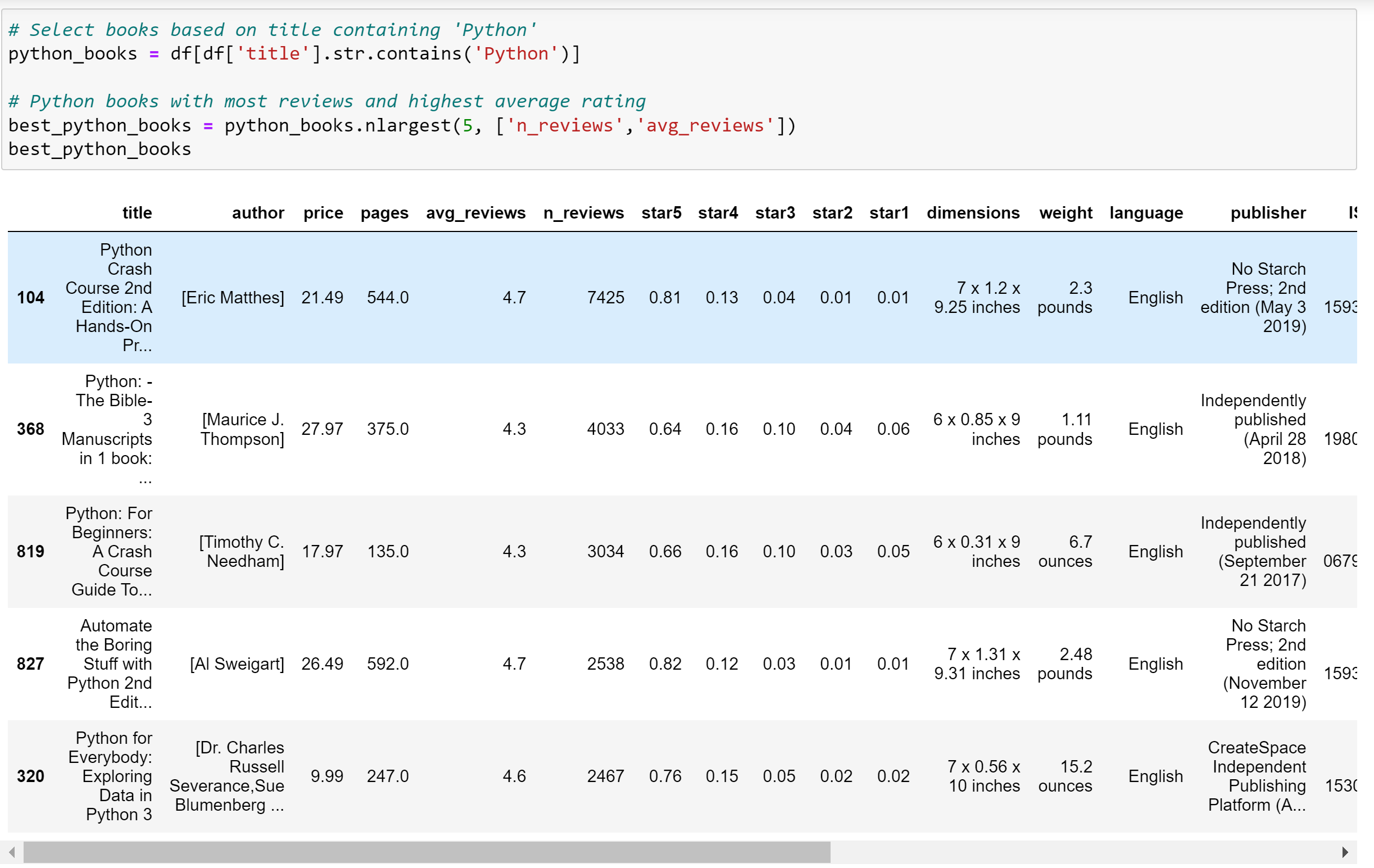
In conclusion, the following are the top 5 books on Python based on the number of reviews: they have between 2500 and 7000 reviews with an average rating between 4.3 and 4.7. These are really excellent books! I highly recommend them, particularly: Python Crash Course
d-Cluster Analysis of books


For the clustering problem, I used the K-Means Nearest Neighbor method. I first used the elbow method to determine the optimal number of book clusters, and then utilized word clouds to display the most important words within each cluster. This allowed me to visually analyze the distinct characteristics of each cluster and gain a better understanding of the overall trends in the data. Overall, the K-Means Nearest Neighbor method proved to be a useful tool for clustering the data and uncovering insights about the books.
Step 2 -Scraping Review from Amazon Website
Initially, I noticed a common pattern in the URLs of each book's Amazon link and its review link. Therefore, I created a function to take the URL of the book and convert it into the URL for its review page. This allowed me to easily scrape the reviews for each book and gather the necessary data for my analysis. Overall, this was an important step in my data collection process as it allowed me to efficiently access the review information for all 1000 books.

In addition, I utilized Jeff James' code to scrape the reviews for each book and put them into a new data frame. This proved to be a valuable resource as it allowed me to quickly and efficiently gather the review data for all of the books. The use of this code streamlined my data collection process and enabled me to focus on the analysis and interpretation of the data.

Step 3 - Sentiment Analysis
VADER Sentiment Scoring
In addition, I conducted sentiment analysis on each review. I used the VADER model, which is the most basic model for sentiment analysis that has a list of English words with a sentiment score (positive or negative) and calculates the average of all the scores of each word in the text to determine the sentiment of the text. The closer the score is to 1, the more positive the sentiment is, the closer it is to -1, the more negative the sentiment is, and 0 is neutral. This provided valuable insights into the overall sentiment of the reviews for each book and allowed me to analyze trends in the data.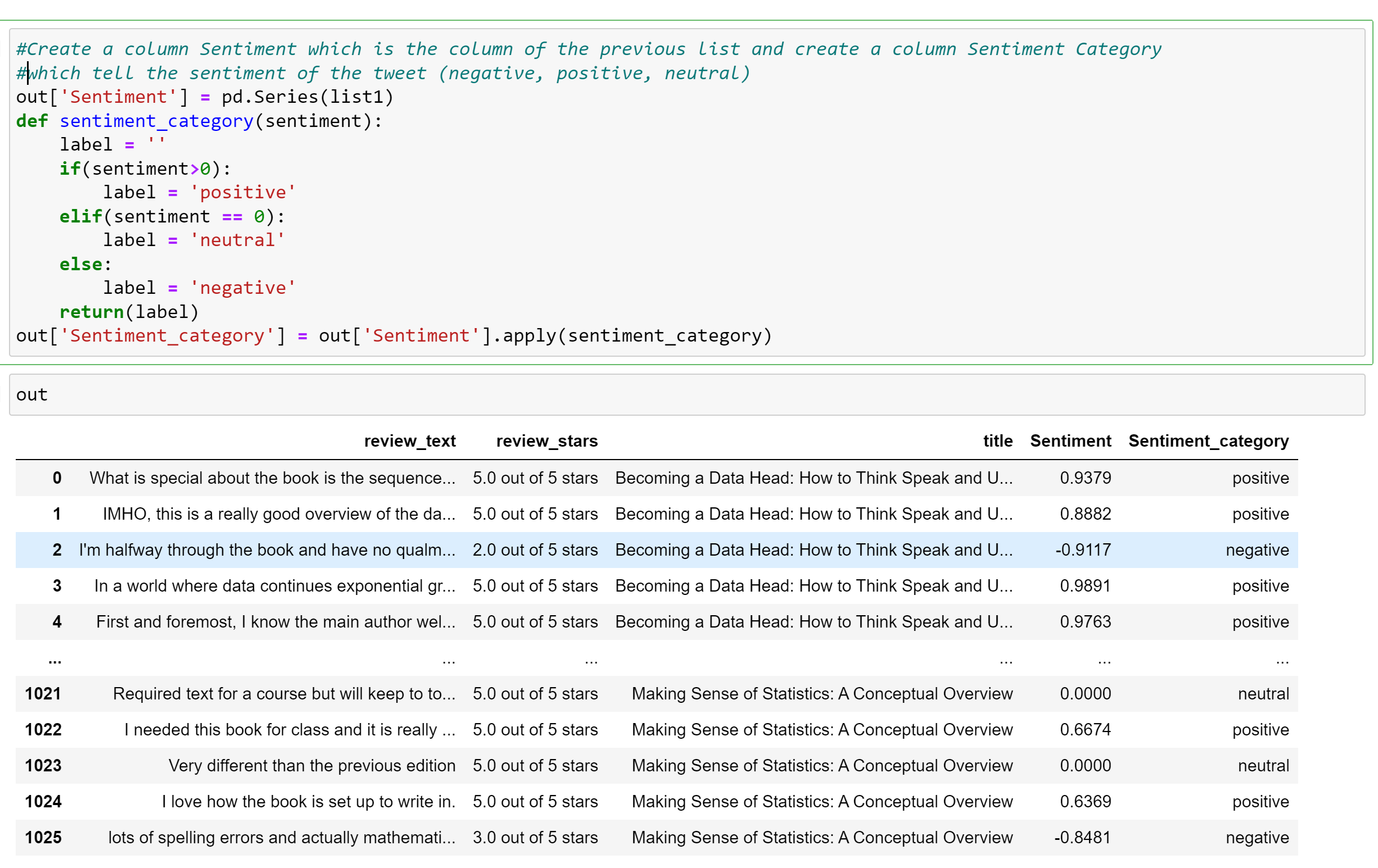
ROBERTA Sentiment Scoring
urthermore, I used the ROBERTA sentiment scoring model, which takes into account the overall context of the text. This model is more accurate and I compared the results of both models. This allowed me to gain a deeper understanding of the sentiment of the reviews and analyze any discrepancies between the two models. 
Conclusion
In summary, I completed a data science project that involved analyzing 1000 data science books on Amazon in order to uncover the most relevant trends and insights. I used various data science techniques and approaches, including exploratory data analysis (EDA), text sentiment analysis, cluster analysis, and text vectorization. I also utilized data scraping techniques to gather Amazon reviews and implemented an automated summary of book reviews. The results of my project showed that the longest books tend to be the ones that sell for the highest price, although other factors such as the reputation of the author and the demand for the subject matter may also influence this trend. Additionally, I used two different sentiment analysis models, VADER and ROBERTA, to gain a deeper understanding of the sentiment of the reviews and analyze trends in the data. Finally, I used the K-Means Nearest Neighbor method and word clouds to perform cluster analysis and uncover insights about the books. In conclusion, this project allowed me to develop my skills in data science and put my knowledge into practice while learning new techniques and approaches. I am happy to share my results and insights with the data science community in order to contribute to its development.